 Scroll Apps for Confluence
Scroll Apps for Confluence
 Backbone Work Sync for Jira
Backbone Work Sync for Jira
 Coming Soon! Scroll Sites
Coming Soon! Scroll Sites
 About Us
About Us
 Careers
Careers
 Partner Program
Partner Program
 Trust Center
Trust Center
 Contact
Contact
 PDF Template Library
PDF Template Library
 Collaboration Hub
Collaboration Hub

Migrating Legacy Content - Best Practices for Importing HTML Pages Into Confluence

teaserImage |
|
|---|---|
metaDescription |
Bringing people together in a collaboration platform like Atlassian Confluence also means transferring your legacy content from multiple information silos. These repositories often contain important information that you can’t afford to leave by the wayside when building a new corporate knowledge base. In many cases, legacy content is only available as HTML files, such as online help resources or intranet pages. |
Bringing people together in a collaboration platform like Atlassian Confluence also means transferring your legacy content from multiple information silos. These repositories often contain important information that you can’t afford to leave by the wayside when building a new corporate knowledge base. In many cases, legacy content is only available as HTML files, such as online help resources or intranet pages.
Is there a way to bring these assets into Confluence efficiently? Yes – but there is no one-size-fits-all method. There are three main approaches to importing a collection of static HTML pages. Your individual needs will determine which is best for you.
Before You Begin
Be critical when planning to migrate large volumes of content. Assess whether all your legacy information is valid for your new platform. Avoid transferring assets to the new platform without having a content strategy. If you have a solid plan, you could significantly reduce migration volumes; this cuts workload, and enhances content quality and findability.
After creating your plan, we recommend checking if there is an alternative option to importing HTML files. Your legacy content may already be available in Word format, or able to be converted into the .docx format.
If your documentation is in Word format, you can use a more efficient method; you can import Word files with ease. With Confluence 5.7, document chapters can be imported as multiple Confluence pages, preserving their hierarchy and order.
Manually Copying Content into the Confluence Editor
If you only have a small quantity to import, or you only need portions of each page’s contents, it may be better to manually copy and paste directly into the Confluence editor.
When copying and pasting, you have complete control over what is imported. For example, you can avoid including outdated or redundant documentation, and exclude navigation elements and other irrelevant material. What’s more, manual migration allows you to refactor all your assets as required.
Tip: When taking a manual approach, consider delegating – ask your colleagues to import one or two pages each. This accelerates the process, and minimizes your need to repeatedly copy and paste.
Batch HTML Import into Confluence
To import large amounts of HTML content, you could use the built-in HTML / text file import functionality. This is accessible from the Confluence space administration interface.
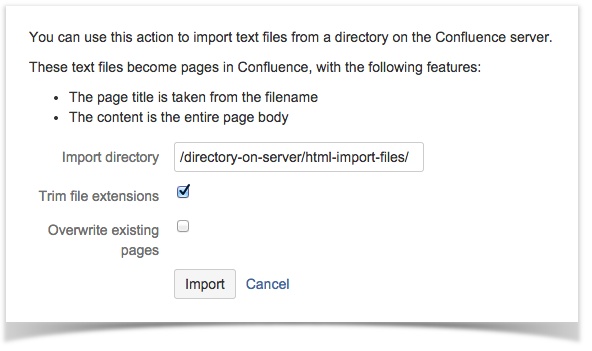
Please note that this approach has several limitations:
Space administrator permissions are required.
You’ll need access to your Confluence server’s file system. This means you can’t upload files from your local computer.
You can’t batch import if you are using Confluence Cloud.
HTML (or text) files are imported to your target Confluence space as a flat list – they will all be on the top level. Batch importing doesn’t preserve page hierarchy, etc.
Graphics, or other resources referenced in the HTML files, will not be imported.
This feature was first included in early Confluence releases, so it doesn’t offer the great usability as other features. However, in some cases, it could be a very useful tool for importing legacy content.
Migrating Content In Style with WebWorks ePublisher
Using WebWorks ePublisher is another option for transferring HTML-based content (or other file formats, such as FrameMaker, DITA XML, etc.) to your Confluence knowledge base. This commercial Windows application allows you to convert content from almost any format, and publish it to several help platforms. The tool allows you to match and adjust styles in numerous ways, clean up the markup, and define your content’s output structure.
It also allows you to generate content for your Confluence wiki, and deploy it with a single click by utilizing Confluence’s remote API and XML RPC API. The following video shows how it’s done. The video is from 2012; Confluence’s look-and-feel has improved significantly since then, but the process remains the same.
For more details on how to convert documentation for Confluence, take a look at this in-depth step-by-step guide by Sarah Maddox.
The Import is Complete – What’s Next?
No matter which method you used, you should examine the import results in detail. In some cases, you may need to correct links or replace navigation elements with Confluence macros such as the Children Display macro.
The context of your migration, such as the data quality of the source content, and the people and tools involved, will determine which approach is best for you.
We at K15t Software may develop a Scroll HTML Importer to go with our Scroll HTML Exporter, leveraging our experience with content migration – for example, importing content from DocBook XML to Confluence. Until then, we recommend using one or more of the approaches described. Alternatively, why not get in touch with us? We’re happy to help.
.png)